什么是 Harness Engineering?
人类约公元前3500年驯化马,又过了三千多年(约公元前1世纪)才出现木质鞍架,再过了四百余年(约公元4世纪)马镫才问世。马鞍没有改变马的速度,却把骑手重量从脊椎分散至肌肉,让人从”附体”变为骑兵——没有它,重装冲锋、草原骑射、丝路商队都无从谈起。
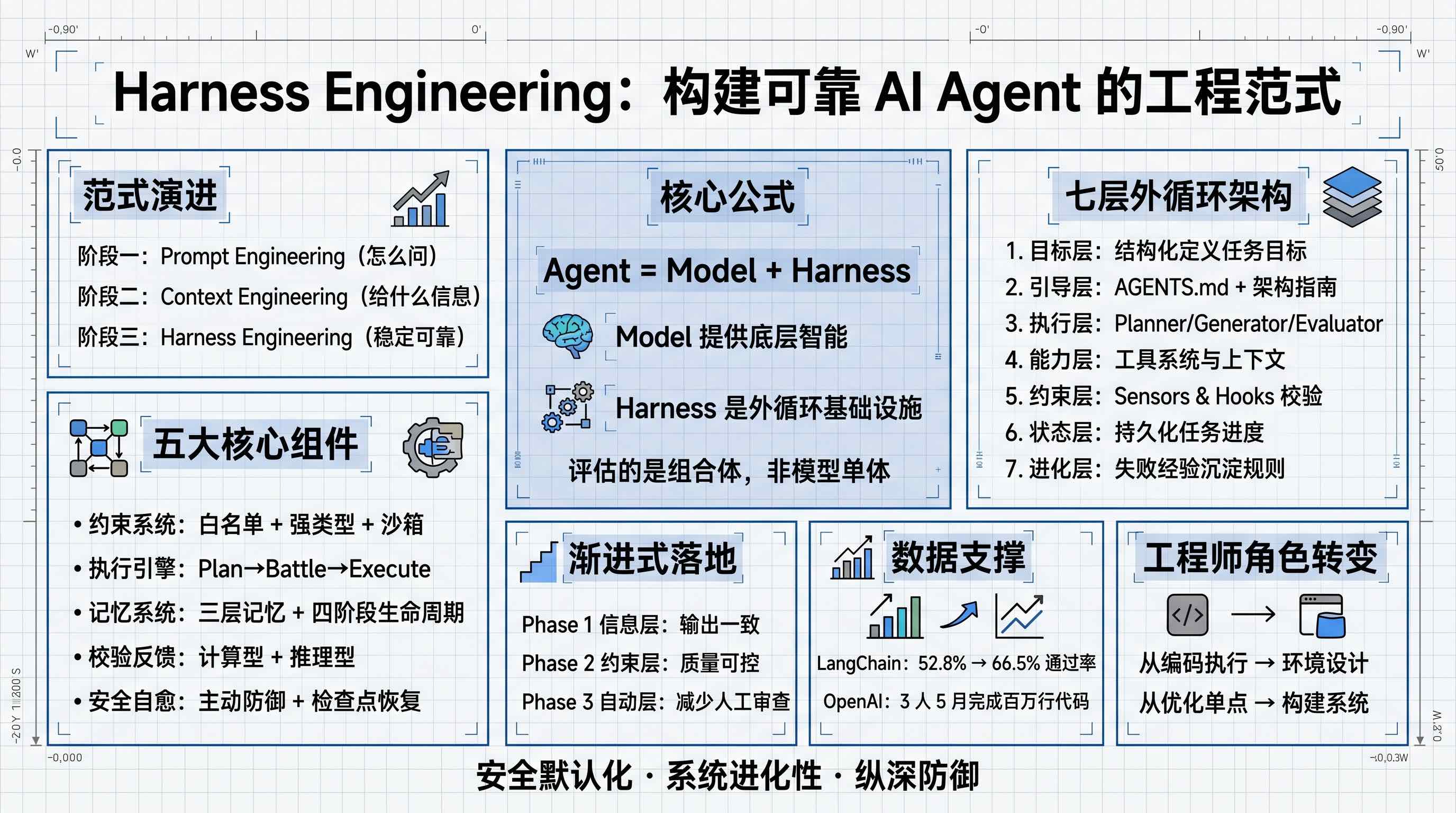
Harness Engineering(约束工程) 是一种为 AI Agent 搭建可运行、可约束工程环境的系统性开发范式。其核心等式为:
Agent = Model + Harness
Model 提供底层智能,Harness 是让这个智能能够可靠、可控运行的外循环基础设施。评估一个 Agent 的效果,评估的是”模型 + 约束系统”这个组合体,而非模型单体。
为什么需要它?
范式演进
AI 工程经历了三个阶段的演进:
| 阶段 | 核心问题 | 解法 |
|---|---|---|
| Prompt Engineering | 怎么问模型才答得好 | 优化 prompt |
| Context Engineering | 怎么给模型足够的信息上下文 | RAG、文档注入 |
| Harness Engineering | 如何让 Agent 在长程任务中稳定可靠 | 构建完整外循环控制系统 |
AI Agent 在复杂任务中反复出错,往往不是因为模型不够智能,而是因为它”看不见”项目的隐式规则——架构分层、命名规范、依赖约定。Harness 将这些规则变得对 AI 可见且可验证。
数据支撑
- LangChain 2026 年 3 月实验:仅通过优化 Harness,同一模型在 Terminal Bench 2.0 上的任务通过率从 52.8% 提升至 66.5%,排名跃升前五。瓶颈往往在基础设施,而非模型智能本身。
- OpenAI 2026 年 2 月案例:3 名工程师在 5 个月内零手写代码,完全依靠 Agent 生成约 100 万行代码,完成 1500 个 Pull Request,效率提升约 90%。背后依赖的正是成熟的 Harness 系统。
核心理念
Harness Engineering 带来了工程师角色的根本性转变:
- **从”编码执行”到”环境设计”**:不再手写每一行代码,而是将业务逻辑、工程判断和团队规范编码为机器可读的约束系统。
- **从”优化单点”到”构建系统”**:焦点从优化单次交互,转向设计和维护能让 Agent 自主、可靠、大规模工作的完整工程系统。
- 安全默认化:在所有设计环节贯彻”默认拒绝、最小权限”原则,构建纵深防御体系。
- 系统进化性:将运行中的失败经验自动沉淀为新规则,使 Harness 越用越完善。
架构:七层外循环系统
Harness 的宏观架构是围绕核心模型(内循环)的七层外循环控制系统,构成从目标输入到可靠输出的完整闭环:
| 层级 | 核心职责 |
|---|---|
| 1. 目标层(意图) | 结构化定义任务目标,是控制回路的起点 |
| 2. 引导层(前馈控制) | AGENTS.md 与架构指南,提供确定性规则和推断性原则 |
| 3. 执行层(Agent 循环) | Planner / Generator / Evaluator 三角色循环,完成计划、执行、评估 |
| 4. 能力层 & 交互层 | 工具系统与上下文管理,按需注入技能,对抗信息膨胀 |
| 5. 约束与反馈层(反馈控制) | Sensors & Hooks,自动化校验,决定继续、停止或回退 |
| 6. 状态与恢复层 | 持久化任务进度与会话状态,支持跨会话可靠恢复 |
| 7. 进化层(反熵治理) | 将失败经验沉淀为新规则,自动清理技术债,实现系统自我演进 |
五大核心组件
一、约束系统(Constraint System)
核心理念:用代码强制执行规则,而非依赖 Prompt 软劝告。
约束系统是 Harness 的”防护栏”,在模型决策之前就划定边界。
关键设计:
- 工具白名单:按任务类型动态注册可用工具,未注册即不可调用
- 强类型参数校验:Pydantic / TypeScript 强类型拒绝非法输入,从入口截断错误
- 操作分级授权:读 → 自动执行;写 → 人工确认;删 → 双重确认
- 沙箱隔离:代码执行、危险操作运行在容器内,主系统不受影响
- 幂等性设计:工具层防重复调用,消除副作用
约束系统解决的是”什么不能做”的问题,越早拦截,修复成本越低。
二、执行引擎(Execution Engine)
核心理念:不同任务需要不同执行策略,一套流程走天下是反模式。
执行引擎负责将模型决策可靠地转化为行动。提供三种可选策略:
| 策略 | 特点 | 适用场景 |
|---|---|---|
| Fixed Workflow | 确定性高,流程固定 | 高频重复任务 |
| ReAct | 边思考边行动,灵活 | 探索性任务,但成本高、不可控 |
| Plan → Battle → Execute | 动态规划 → 辩论验证 → 确认执行 | 推荐,复杂任务首选 |
Plan-Battle-Execute 模式的关键在于在执行前引入”辩论验证”环节,由独立的 Battle Agent 对计划提出质疑,暴露潜在风险,再交由人工确认后进入确定性执行阶段。
执行引擎解决的是”怎么做”的问题,过程的确定性决定结果的可信度。
三、记忆系统(Memory System)
核心理念:上下文是有限资源,超过 40% 利用率后推理质量显著下降,必须主动管理。
记忆系统分三层独立管理,避免信息污染与上下文膨胀:
1 | ┌─────────────────────────────────┐ |
生命周期四阶段:注入 → 监控 → 压缩 → 归档
- 超 40% Token 阈值时触发压缩:摘要化历史、裁剪低优先级内容
- 保留决策结论与关键事实,丢弃推理链与失败路径
- 后台”蒸馏”机制(类”做梦”):定期去重、合并、整合零散记忆,迁移至持久知识库
多 Agent 场景下,子 Agent 使用全新上下文,通过结构化消息传递信息,禁止共享原始上下文,错误状态不向下游传播。
记忆系统解决的是”该知道什么”的问题,信息质量比信息数量更重要。
四、校验与反馈(Verification & Feedback)
核心理念:让结果可信,靠验证而非信任。
校验层内置于执行流程每个关键节点,而非仅在最终输出时检查。
两类校验机制:
| 类型 | 执行者 | 速度 | 适用场景 |
|---|---|---|---|
| 计算型校验 | 确定性脚本 | 快,零额外 Token | 语法、格式、调用规范、单元测试 |
| 推理型校验 | 独立评估 Agent | 慢,成本高 | 语义判断、架构方向、安全风险 |
生成者与评估者分离(受 GAN 启发):评估 Agent 独立于生成 Agent,避免”自我说服”的系统性乐观偏见,且可对评估者单独进行”偏向严格”的调优。
四个验证节点:
- 前置验证:任务开始前检查环境、权限、格式
- 步骤后验证:每步执行后检查输出与状态变更
- 进展检测:状态指纹比对,识别原地循环
- 终止检查:最大迭代次数 + 时间预算 + 停滞阈值
校验层解决的是”做对了吗”的问题,可观测性是一等公民——只有能被看见的,才能被信任。
五、安全与自愈(Safety & Self-Healing)
核心理念:不假设系统不会出错,而是设计好出错后的恢复路径。
安全设计分两个维度:
主动防御(Safety)
- 多模型并行安全检测:放弃单一大 Prompt 做安全审查(易 Lost in Middle),改用多个专职小模型并行检测安全性、合规性、敏感内容,结果汇总判断
- 最小权限暴露:工具只暴露当前任务必要的能力
- Prompt Cache:缓存重复提示,降低攻击面,同时控制成本
被动自愈(Self-Healing)
- 故障隔离:一个 Agent 的错误不向下游传播
- 重试与降级:失败后按策略重试或切换降级方案
- 检查点恢复:阶段性任务完成后保存状态快照,出错从最近检查点恢复而非从头重来
- 规则冲突检测:自动识别矛盾指令并告警,防止系统进入不确定状态
安全与自愈解决的是”出错了怎么办”的问题,系统的可靠性不来自于从不出错,而来自于出错后能快速恢复。
多 Agent 协调与故障隔离
复杂任务采用主 Session 作为 Orchestrator,创建多个 Worker Agent 并行处理。可靠性通过隔离来保障:
- Worker 之间不共享原始上下文,只传递结构化消息,防止上下文污染
- 每个 Worker 拥有独立会话上下文,一个 Worker 崩溃不会导致级联故障
- Orchestrator 负责监控所有 Worker 状态、错误重试调度和最终结果合成
渐进式落地策略
Harness Engineering 的落地是渐进式的,切勿一步到位:
| 阶段 | 目标 | 关键动作 |
|---|---|---|
| Phase 1:信息层 | Agent 输出一致 | AGENTS.md + 结构化文档 + 编码规范文档化 |
| Phase 2:约束层 | 代码质量可控 | 分层架构 + 静态代码分析 + CI 约束检查 |
| Phase 3:自动化层 | 减少人工审查 | Agent 自验证闭环 + 自动化质量门禁 |
Phase 1 做扎实是质变的前提,过早追求自动化会导致约束和验证体系尚未成熟时 Agent 失控。
常见反模式
- 层级混淆:将过多内容塞入 AGENTS.md,挤占上下文窗口
- 过度工具化:Agent 过度依赖工具,失去自主判断能力
- 过早追求自治:约束和验证体系不完善时追求 Agent 完全自主
- 规则过密:约束太多反而限制 Agent 创造力
- 缺乏 Human-in-the-Loop:关键节点缺少人工复核机制
- 忽视可维护性:Harness 本身需要版本管理和持续迭代
与 SDD(Spec-Driven Development,规范驱动开发)的关系
Harness Engineering 是 SDD 的执行层,二者互补而非替代:
- SDD 解决”做什么”和”怎么验证”——以规格文档作为单一事实来源,驱动设计、实现与验证全流程
- Harness Engineering 解决”Agent 怎么可靠地执行 SDD 定义的方案”——提供约束、上下文、验证闭环与状态管理
没有 SDD,Harness 是盲目的;没有 Harness,SDD 无法落地。
未来方向:Meta-Harness
斯坦福、MIT 等机构提出 Meta-Harness 框架:不再只优化单条 prompt,而是把完整 Harness 程序作为优化对象,让 Agent 自主检索历史失败原因并改写 Harness,将系统优化过程自动化。
实验数据显示,Meta-Harness 在在线文本分类任务上准确率从 40.9% 提升至 48.6%,同时上下文开销从 50.8K tokens 降至 11.4K。
总结
| 维度 | 结论 |
|---|---|
| 本质 | 在模型之外,给 Agent 搭建”可读、可控、可验证、可恢复”的外循环运行环境 |
| 核心公式 | Agent = Model + Harness |
| 解决的问题 | AI 在长程任务中的稳定性、可靠性、可维护性 |
| 不需要做 | 微调模型、换模型 |
| 关键动作 | 约束设计 + 上下文注入 + 验证闭环 + 状态管理 + 安全纵深防御 |
| 落地策略 | 渐进式三阶段(信息层 → 约束层 → 自动化层) |
| 工程师角色转变 | 从编码执行者 → 系统架构师与环境设计师 |
信息图